 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact solution of the full RMSA problem in elastic optical networks
Sep 14, 2023Exact solutions of the Routing, Modulation, and Spectrum Allocation (RMSA) problem in Elastic Optical Networks (EONs), so that the number of admitted demands is maximized while those of regenerators and frequency slots used are minimized, require a complex ILP formulation taking into account frequency-slot continuity and contiguity. We introduce the first such formulation, ending a hiatus of some years since the last ILP formulation for a much simpler RMSA variation was introduced. By exploiting a number of problem and solver specificities, we use the NSFNET topology to illustrate the practicality and importance of obtaining exact solutions.
Shape complexity in cluster analysis
May 18, 2022
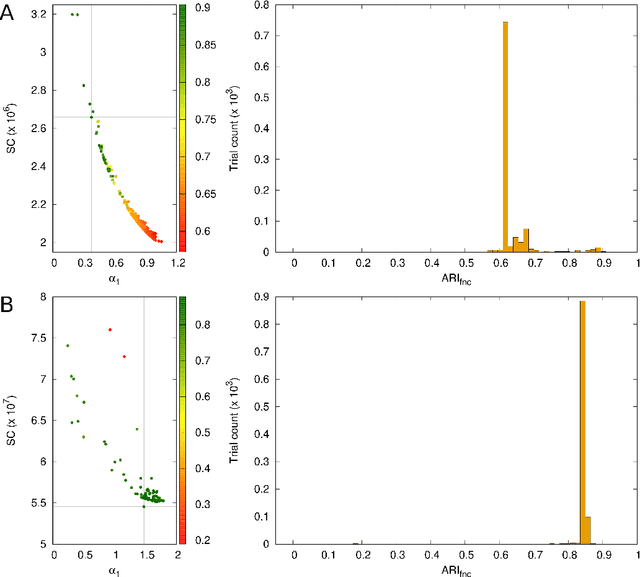
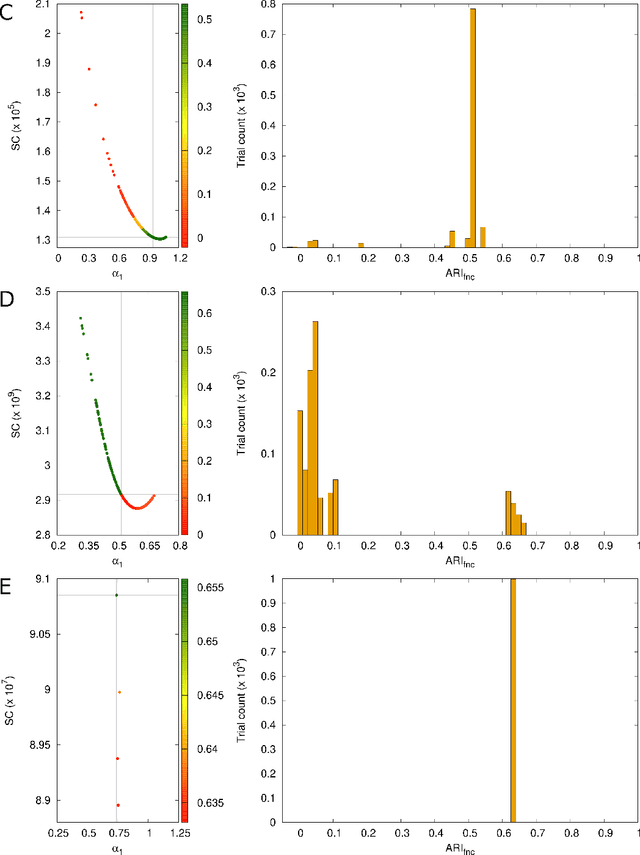
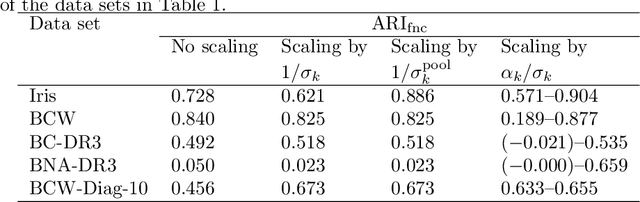
In cluster analysis, a common first step is to scale the data aiming to better partition them into clusters. Even though many different techniques have throughout many years been introduced to this end, it is probably fair to say that the workhorse in this preprocessing phase has been to divide the data by the standard deviation along each dimension. Like division by the standard deviation, the great majority of scaling techniques can be said to have roots in some sort of statistical take on the data. Here we explore the use of multidimensional shapes of data, aiming to obtain scaling factors for use prior to clustering by some method, like k-means, that makes explicit use of distances between samples. We borrow from the field of cosmology and related areas the recently introduced notion of shape complexity, which in the variant we use is a relatively simple, data-dependent nonlinear function that we show can be used to help with the determination of appropriate scaling factors. Focusing on what might be called "midrange" distances, we formulate a constrained nonlinear programming problem and use it to produce candidate scaling-factor sets that can be sifted on the basis of further considerations of the data, say via expert knowledge. We give results on some iconic data sets, highlighting the strengths and potential weaknesses of the new approach. These results are generally positive across all the data sets used.
The conduciveness of CA-rule graphs
Apr 27, 2012Given two subsets A and B of nodes in a directed graph, the conduciveness of the graph from A to B is the ratio representing how many of the edges outgoing from nodes in A are incoming to nodes in B. When the graph's nodes stand for the possible solutions to certain problems of combinatorial optimization, choosing its edges appropriately has been shown to lead to conduciveness properties that provide useful insight into the performance of algorithms to solve those problems. Here we study the conduciveness of CA-rule graphs, that is, graphs whose node set is the set of all CA rules given a cell's number of possible states and neighborhood size. We consider several different edge sets interconnecting these nodes, both deterministic and random ones, and derive analytical expressions for the resulting graph's conduciveness toward rules having a fixed number of non-quiescent entries. We demonstrate that one of the random edge sets, characterized by allowing nodes to be sparsely interconnected across any Hamming distance between the corresponding rules, has the potential of providing reasonable conduciveness toward the desired rules. We conjecture that this may lie at the bottom of the best strategies known to date for discovering complex rules to solve specific problems, all of an evolutionary nature.
Evolved preambles for MAX-SAT heuristics
Feb 18, 2011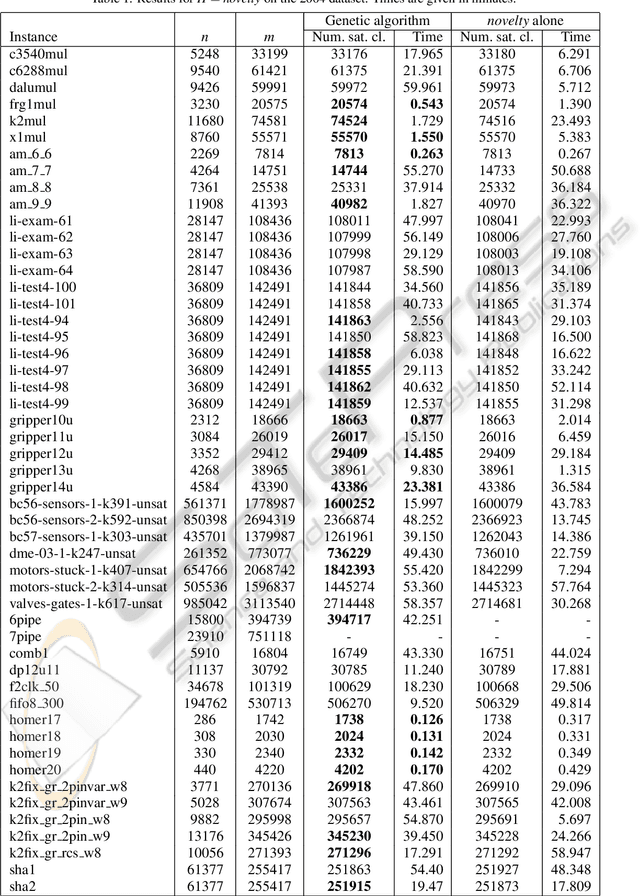
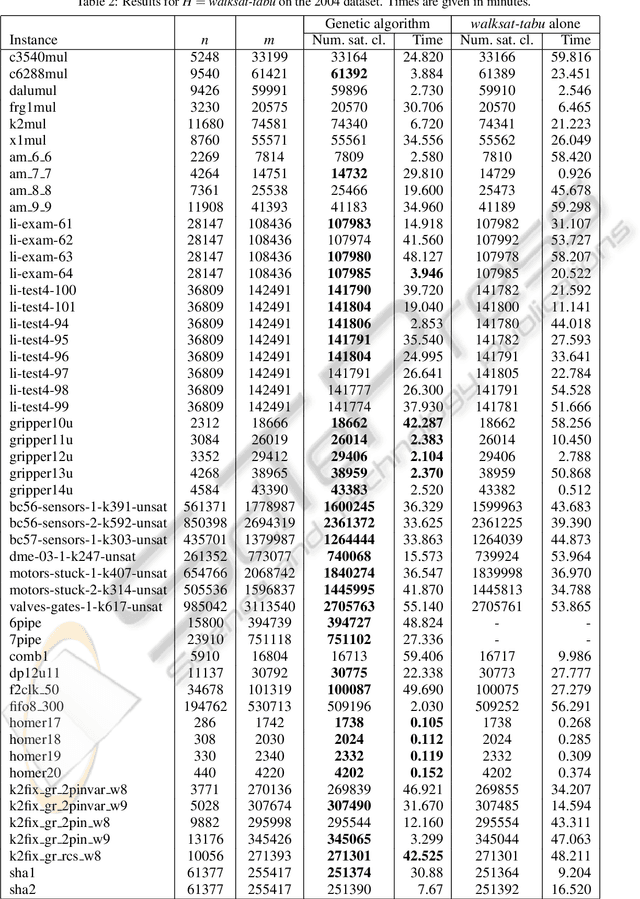
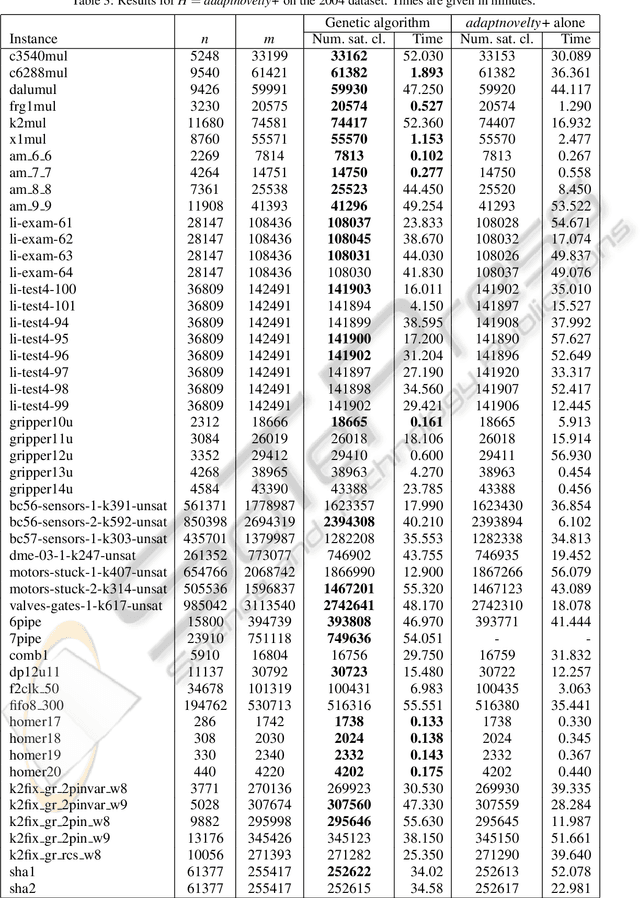
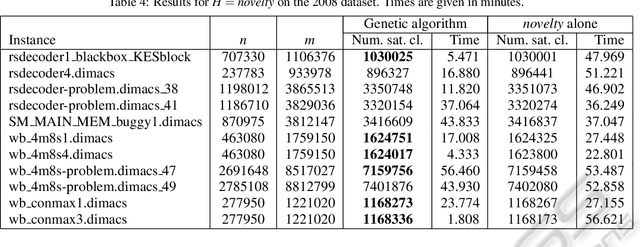
MAX-SAT heuristics normally operate from random initial truth assignments to the variables. We consider the use of what we call preambles, which are sequences of variables with corresponding single-variable assignment actions intended to be used to determine a more suitable initial truth assignment for a given problem instance and a given heuristic. For a number of well established MAX-SAT heuristics and benchmark instances, we demonstrate that preambles can be evolved by a genetic algorithm such that the heuristics are outperformed in a significant fraction of the cases.
Optimization of supply diversity for the self-assembly of simple objects in two and three dimensions
Oct 04, 2007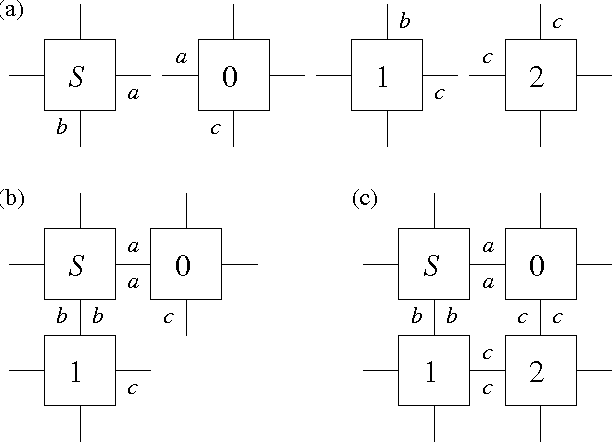

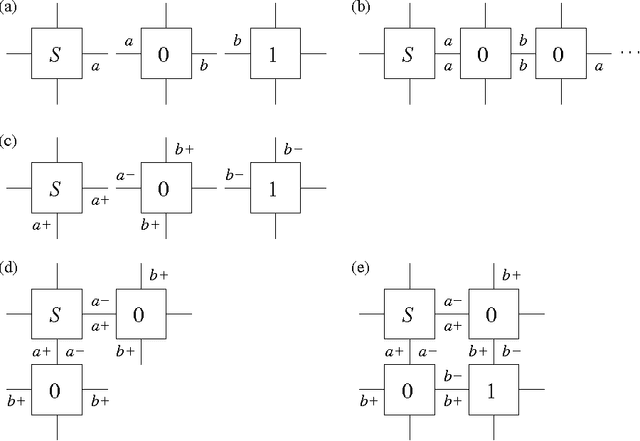
The field of algorithmic self-assembly is concerned with the design and analysis of self-assembly systems from a computational perspective, that is, from the perspective of mathematical problems whose study may give insight into the natural processes through which elementary objects self-assemble into more complex ones. One of the main problems of algorithmic self-assembly is the minimum tile set problem (MTSP), which asks for a collection of types of elementary objects (called tiles) to be found for the self-assembly of an object having a pre-established shape. Such a collection is to be as concise as possible, thus minimizing supply diversity, while satisfying a set of stringent constraints having to do with the termination and other properties of the self-assembly process from its tile types. We present a study of what we think is the first practical approach to MTSP. Our study starts with the introduction of an evolutionary heuristic to tackle MTSP and includes results from extensive experimentation with the heuristic on the self-assembly of simple objects in two and three dimensions. The heuristic we introduce combines classic elements from the field of evolutionary computation with a problem-specific variant of Pareto dominance into a multi-objective approach to MTSP.
* Minor typos corrected
V-like formations in flocks of artificial birds
Apr 08, 2007We consider flocks of artificial birds and study the emergence of V-like formations during flight. We introduce a small set of fully distributed positioning rules to guide the birds' movements and demonstrate, by means of simulations, that they tend to lead to stabilization into several of the well-known V-like formations that have been observed in nature. We also provide quantitative indicators that we believe are closely related to achieving V-like formations, and study their behavior over a large set of independent simulations.
Two-dimensional cellular automata and the analysis of correlated time series
Jul 08, 2005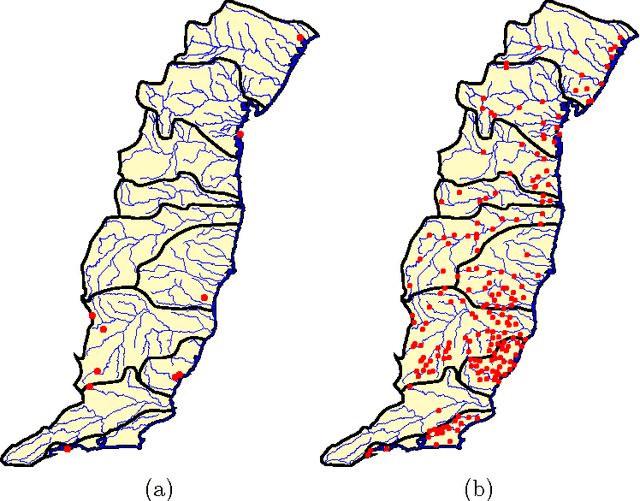
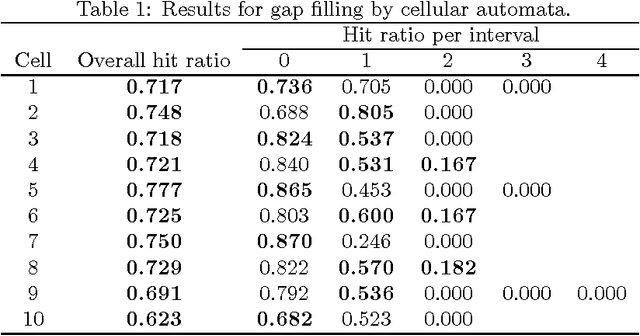
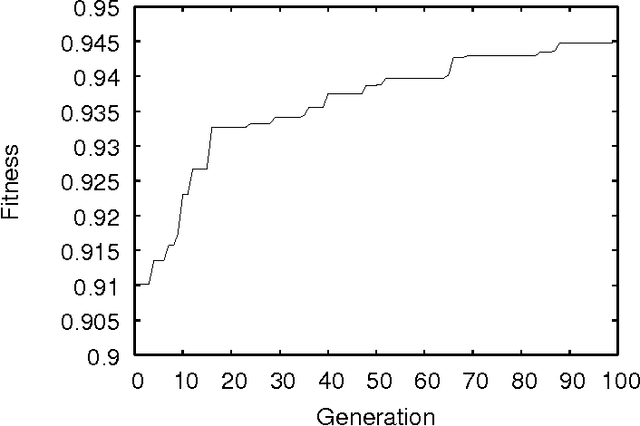
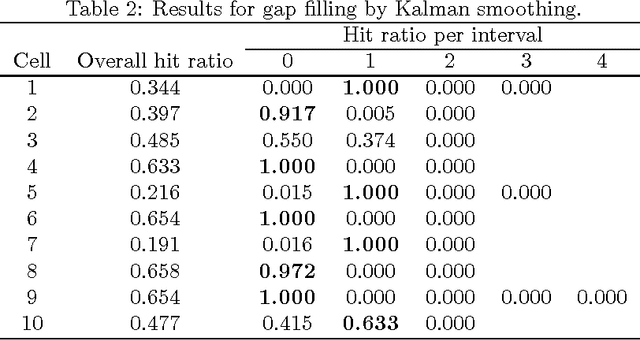
Correlated time series are time series that, by virtue of the underlying process to which they refer, are expected to influence each other strongly. We introduce a novel approach to handle such time series, one that models their interaction as a two-dimensional cellular automaton and therefore allows them to be treated as a single entity. We apply our approach to the problems of filling gaps and predicting values in rainfall time series. Computational results show that the new approach compares favorably to Kalman smoothing and filtering.